De magische fusie tussen batch- en streaming-insights
Bedrijven hebben datagedreven insights nodig om stakeholders en klanten zo snel mogelijk te bereiken, met duidelijk gedefinieerde versheidseisen. De Lambda-architectuur (Marz 2015) lost deze eisen op door insights uit batchprocessen en real-time streams te combineren tot een up-to-date dataproduct. Wij stellen dat de Lambda-architectuur een relevante aanpak blijft om insights te leveren voor data science-teams met beperkte engineeringcapaciteit. We gaan in op de creatieve manieren om batch- en streaming-insights te fuseren en presenteren onze Azure Lambda-implementatie, ter illustratie.
Overzicht van de Lambda-architectuur
De Lambda-architectuur werd helder uiteengezet door Nathan Marz (boek, 2015). De Lambda-architectuur bestaat uit een batch layer, een speed layer en een serving layer en is gericht op het leveren van up-to-date insights. De batch layer gebruikt de master dataset om de batch view bij elke run te overschrijven. Deze voorberekende batch-insights zijn onze source of truth. Tussen de batch pipeline-runs door worden streaming-updates uit de speed layer gebruikt om onze insights vers te houden. Dit is best effort, want eventuele fouten die zich ophopen uit streaming-updates worden bij de volgende batch pipeline-run weggegooid. De serving layer combineert de batch- en real-time view tot een up-to-date dataproduct als antwoord op queries.
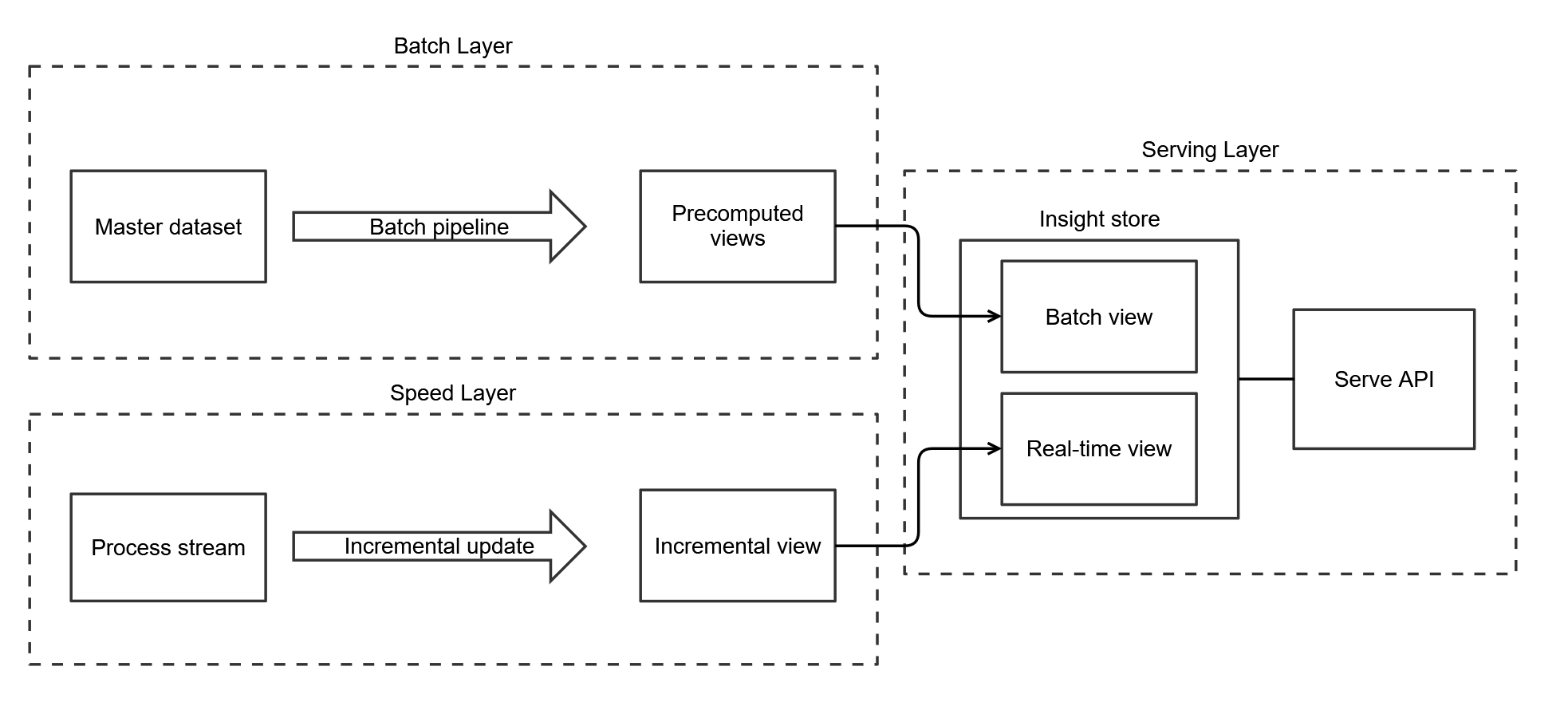
Lambda voor data science
De Lambda-architectuur is geschikt voor moderne data science-teams die real-time insights aan business en klanten willen leveren. Vaak is er al een batch layer aanwezig en is de behoefte aan versere insights een aanvullende eis. Het bestaan van een batch layer kan ook goede redenen hebben, zoals aggregaties of het trainen van machine learning-modellen op historische data. De samenstelling van een data science-team met zo’n 30% data engineering-capaciteit past goed bij de pragmatische self-healing-eigenschap van de Lambda-architectuur.
Waarom geen kappa?
Bij de Kappa-architectuur draait alles om volwaardige event sourcing. De source of truth is niet de batch pipeline (die ontbreekt), maar de geaccumuleerde state over alle voorgaande streaming-events. Er zijn blogs (zoals deze) die mislukte projecten op basis van event sourcing beschrijven. Een van de lastigere dingen om te beheren is error recovery. Stel je voor dat je een fout hebt gemaakt in je streaming-logica en een hotfix klaar hebt staan. In Lambda zouden we de fix uitrollen naar de speed layer en zou een getriggerde of geplande run van de batch layer onze insight store zelf herstellen. In Kappa zouden we een groot deel van de historische streaming-events opnieuw moeten afspelen, mogelijk verdeeld over meerdere applicaties en eventhubs (parsers, insight producers), en onze nieuwe state moeten valideren tegen onze verwachtingen. Dit is engineering-intensiever en niet de beste keuze voor een data science-team met beperkte engineeringcapaciteit.
De magische fusie tussen batch- en speed layers
De synergie tussen de batch layer en de speed layer is waar de magie gebeurt. Het is vaak een creatief proces om de Lambda-architectuur toe te passen. Het doel is om de logica in de serving layer tot een minimum te beperken met een passende structuur van de batch- en real-time views. Er zijn drie algemene manieren om de batch layer en de speed layer te fuseren, en deze sluiten elkaar niet uit, namelijk:
- Voorberekende aggregaten in de batch view bijwerken met streaming-insights
- Een door de batch gegenereerde lookup table of ML-model gebruiken in de speed layer
- State-updates van business entities (geaccumuleerd, volledig of gedeeltelijk)
- Bijvoorbeeld het bijwerken van het voorspelde rekeningsaldo van een klant
In deze sectie laten we implementatiedetails achterwege en wanneer we een Kafka-topic noemen, bedoelen we elke event log, zoals Azure eventhub of Kafka zelf.
1 Voorberekende aggregaten bijwerken
Deze fusie kwam uitgebreid aan bod bij Marz (2015). De batch layer berekent aggregaten voor als onze terugkerende source of truth. Streaming-updates worden gecombineerd met historische aggregaten om queries te beantwoorden met up-to-date aggregaten. In het klassieke voorbeeld van bezoekersaantallen van een website worden aggregaten per uur gepartitioneerd in de batch view. Real-time sitebezoeken worden met timestamps opgeslagen in de real-time view (bij voorkeur een key-value store). Een REST-call triggert een functie die zowel de historische aggregaten per uur als alle beschikbare real-time bezoeken ontvangt. De bijgewerkte aggregaten worden berekend en als ons antwoord teruggegeven. Merk op dat de teruggegeven aggregaten andere aggregatieperioden kunnen hebben (bijvoorbeeld dagen, maanden) dan die in de batch view zijn opgeslagen.
1.1 Query-optimalisatie
De aggregaten van sitebezoeken kunnen opnieuw worden berekend met streaming-sitebezoeken die ouder zijn dan een uur en weer worden opgeslagen in de batch view. De verwerkte sitebezoeken uit de speed layer kunnen vervolgens worden weggegooid, wat de responstijden van queries verkort.
1.2 Variaties op insight-aggregatie
De Lambda-architectuur is flexibel in haar toepassing. Er zijn diverse scenario’s die bij de aggregatiefusie passen, maar met een twist.
- We geven de union van batch- en real-time insights terug.
- We willen identifiers in de batch view hashen met een wisselende salt uit de real-time view om onze antwoorden te anonimiseren
- Bayesiaanse correctie van opgeslagen modelvoorspellingen op basis van real-time bewijs
2 Door de batch gegenereerde lookup table of ML-model
Vaak hebben we een tussenproduct uit de batch layer nodig om insights te genereren in de speed layer. Zo worden een lookup table en een getraind ML-model die in de batch layer zijn aangemaakt, gebruikt om insights in de speed layer te verrijken en te classificeren. De batch pipeline maakt bij elke run nieuwe versies van deze artefacten. Vaak willen we alleen de nieuwste versies gebruiken, maar voor ML-modellen kan MLOps worden toegepast om te beslissen het nieuwste model alleen te gebruiken als het beter is dan een vorige versie.
2.1 Lookup table
Hoe delen we een lookup table tussen de batch layer en de speed layer? Een basale aanpak laat de batch layer de lookup table naar storage schrijven. De batch pipeline zou de stream processing in de speed layer kunnen herstarten om een herlaadactie van de nieuwste versie van de opgeslagen lookup table af te dwingen, al is dat niet zo elegant. Eleganter is om de lookup table met een vast interval vanaf disk te herladen zonder onze stream processing te onderbreken (implementatiedetails volgen later). Een andere aanpak is om de lookup table en de versies ervan naar een Kafka-topic te schrijven en deze in de speed layer met een stream-stream join te koppelen. Deze laatste aanpak zou extra complexiteit vereisen om alleen de nieuwste versie van de lookup table te gebruiken, zoals log compaction.

2.2 Getraind ML-model
Voor getrainde ML-modellen die door de batch layer zijn aangemaakt, gaan we uit van geversioneerde modellen die in het model registry zijn opgeslagen en achter hun eigen REST API zijn gedeployed (weergegeven met AzureML inference deployments). We streamen elke unieke URL van een modelversie naar een Kafka-topic met bijbehorende metadata (weergegeven met Azure eventhub). De metadata bevat een voorspellingsdatumbereik waarvoor de modelversie van toepassing is. We joinen de berichten uit de speed layer met de eventhub van model-URL’s op basis van de voorspellingsdatum en roepen de model-API aan om de voorspelling te verkrijgen, die in onze streaming-insight wordt verwerkt.

3 State-updates
De derde manier om batch- en streaming-insights te fuseren, is door te focussen op state management van business entities. Enkele voorbeelden zijn:
- Real-time gegenereerde voorspellingen per klant overrulen de voorspellingen in de batch view
- Voorspelde transacties markeren als verwerkte transacties op basis van de real-time transactiestream
- De credit rating van een klant bijwerken op basis van de real-time output van diverse modellen
Deze stateful fusie verschilt van de fusie beschreven in sectie 1, omdat aggregaten insights leveren over business entities en tijd heen. Hier willen we de insight-state beheren op het niveau van individuele klanten, met gedetailleerde informatie die door de batch- en speed layers stroomt. State management in real-time analytische systemen is lastig, vanwege de niet-gegarandeerde verwerkingsvolgorde van events, librarybeperkingen, datastore-performance en logische complexiteit.
3.1 Business entities en object constancy
Insights doen uitspraken over business entities, zoals de voorspelde waarde van een klant, de drukte in een specifieke trein of het sentiment van een forumgebruiker. Vanzelfsprekend wordt voor elke business entity een aparte state bijgehouden in de insight store. Om state-scheiding mogelijk te maken, moeten we business entities consistent identificeren door ons hele systeem heen, wat object constancy vormt. Er zijn een paar manieren om business entities te identificeren.
- Een unieke data product key (unieke combinatie van veldwaarden, zoals customer_id, bank_account_number)
- Een match scoring-functie die insights matcht met opgeslagen insights
- Similarity-metrics
- Unsupervised clustering
- MinHash of andere bucketing-aanpakken
- Custom scoring-functies
- Een combinatie van de vorige twee
We illustreren de derde optie (gecombineerde aanpak) met banktransacties. Elke transactie heeft een uniek verzendend en ontvangend bankrekeningnummer, die samen een unieke data product key vormen. De twee bankrekeningnummers samen identificeren een financiële relatie. Neem bijvoorbeeld de financiële relatie tussen een student en een universiteit: we zouden transacties met verschillende onderwerpen kunnen zien. Zoals reguliere collegegeldbetalingen door de student en incidentele betalingen voor studiemateriaal. In dit geval willen we de kosten van studiemateriaal voor volgend jaar voorspellen. Om deze twee groepen transacties te ontwarren, scoren we hun overeenkomst op transactiebericht en bedrag. We eindigen met twee sets transacties onder één financiële relatie. Deze twee sets zijn beide business entities en we willen er één selecteren voor onze insight-generatie en state management.
3.2 Volledige state-update
Bij volledige state-updates overrulen de insights uit de speed layer de insights uit de batch layer. Effectief vervangen insights in de real-time view de insights in de batch view. De insights in de batch view hoeven niet te worden overschreven, maar de serving-logica geeft de real-time view voorrang bij het beantwoorden van queries.
3.3 Gedeeltelijke state-updates
De speed layer is mogelijk niet in staat om een complete insight te genereren en beperkt zich tot gedeeltelijke updates. Zo worden state-transities vaak gecommuniceerd via gedeeltelijke state-updates, zoals het laten overgaan van een voorspelling naar een historisch feit. Hier werken we de definitieve waarde bij en de state van het record van voorspeld naar daadwerkelijk. Bij gedeeltelijke updates gebruiken we vaak één enkele view in de serving layer (Fig. 4). De batch layer overschrijft deze enkele view (en zorgt voor het verwijderen van records) en de speed layer patcht records/documents in dezelfde view. Dit houdt de architectuur self-healing, aangezien elke batch pipeline-run de insight store volledig overschrijft.
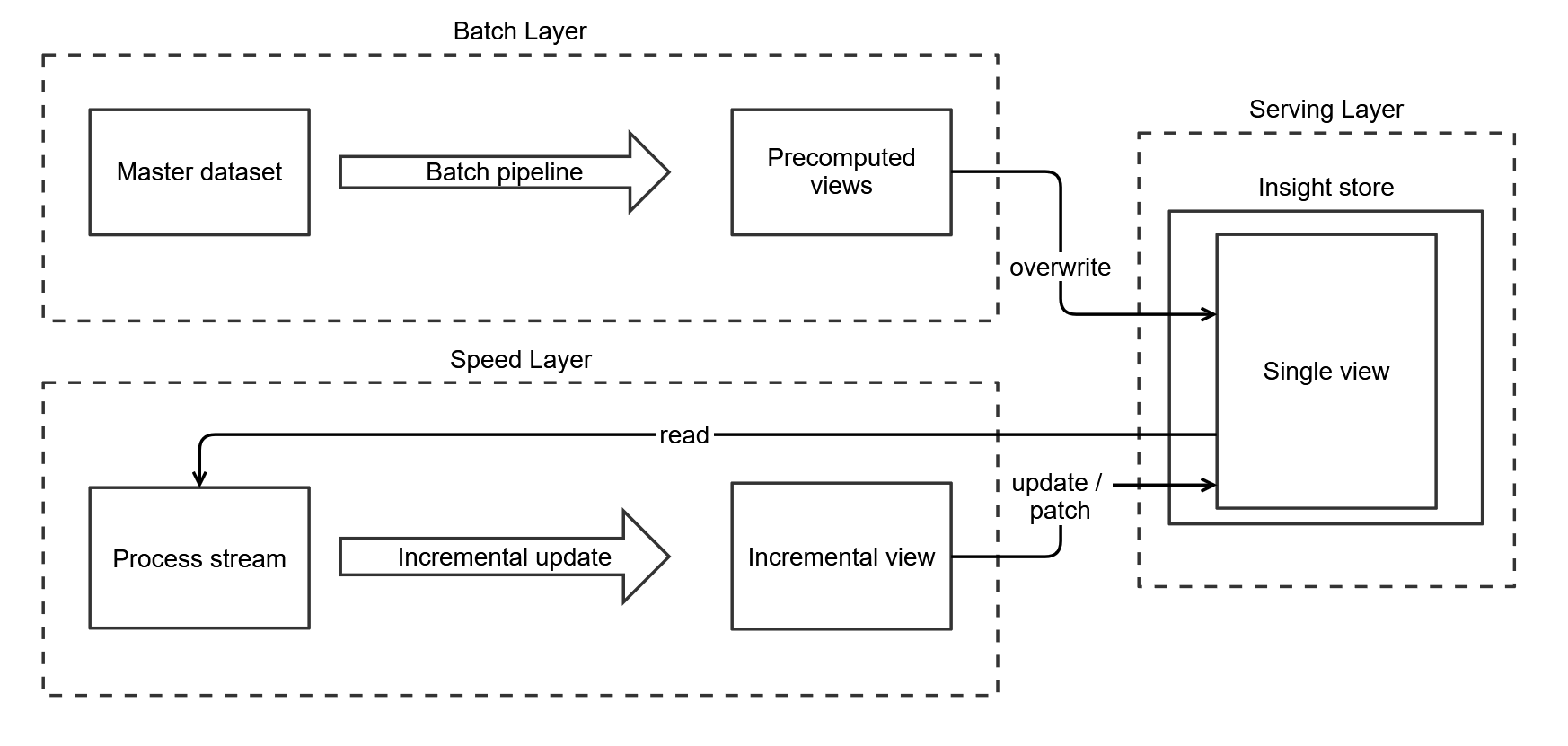
3.4 Geaccumuleerde state-updates
Geaccumuleerde state-updates zijn niet idempotent, omdat de uitkomst van de state-update afhangt van de huidige state. Dit verschilt van volledige of gedeeltelijke state-overrules en wordt lastiger te onderhouden in high-throughput (>100 updates per seconde) streaming-systemen. Naast andere algemene streaming-beperkingen kampen micro batch streaming-frameworks met concurrency-problemen wanneer updates over gelijktijdige micro batches dezelfde state aansturen. Daarom kunnen geaccumuleerde state-updates continue stream processing vereisen. Enkele voorbeelden van state-accumulatie zijn:
- Een lijst voorspelde banktransacties als “verwerkt” markeren met real-time transacties
- Een voorspellingswaarde accumuleren op basis van input van verschillende modellen op verschillende momenten
Net als bij gedeeltelijke updates sinken we zowel de batch layer als de speed layer naar één enkele insight store-view. De batch layer overschrijft de insight-state om de self-healing-eigenschappen van de Lambda-architectuur te behouden, en de speed layer muteert deze. Accumulatieve updates lezen de huidige insight-state, muteren deze en overschrijven deze. Hiervoor hebben we een snelle key-value store nodig om snelle operaties op het niveau van individuele business entities te ondersteunen, zoals HBase.
Azure data science Lambda-architectuur
Elke implementatie van de Lambda-architectuur is anders, vanwege beschikbare technologie en businesseisen. Wij leveren AI-dataproducten als onderdeel van een Advanced Analytics-afdeling. Onze taal is Python, en die gebruiken we overal. Ons AI-team is toegewijd aan Spark en Databricks voor batchverwerking, wat op natuurlijke wijze werd uitgebreid naar stream processing met PySpark structured streaming en andere Azure-aanbiedingen (eventhubs, functions en de niet getoonde stream analytics). Azure eventhubs staan centraal in de stream processing en zijn ook waardevol voor batchresultaten.

Batch layer
De batch pipeline draait twee keer per dag, ‘s nachts en rond het middaguur. Een belangrijke bron voor onze voorspellingen wordt de hele dag door gestreamd en de extra run rond het middaguur verbetert onze voorspellingen sterk. De resultaten van de batch pipeline worden direct in een CosmosDB batch view-container geladen door een batch view loader-applicatie. De state opbouwen in CosmosDB vanuit de batch eventhub zou ideaal zijn, maar voorlopig lijkt de performance de voorkeur te geven aan de spark connector. De twee dagelijkse runs overschrijven elkaars resultaten in CosmosDB, en beide runs schrijven hun resultaten naar de batch eventhub voor downstream-consumptie. Elk bericht in de eventhub is één document in CosmosDB en is één voorspelling die door onze modellen in een gestandaardiseerd formaat is gegenereerd.
Speed Layer
De speed layer consumeert een subset van upstream-bronnen en schrijft deze, na het parsen ervan, naar eventhubs binnen ons domein. Dergelijke single source parsing-logica wordt uitgevoerd op een azure function met een eventhub trigger en output binding. De domein-eventhubs worden geconsumeerd door onze belangrijkste PySpark structured streaming Databricks-applicatie, die de incrementele updates genereert en deze naar de updates-eventhub schrijft voor downstream-consumptie en het laden in de CosmosDB real-time view. De azure function eventhub trigger om CosmosDB te laden is haalbaar vanwege de lagere piekbelasting in vergelijking met de batch layer. Momenteel overrulen we de state in de batch view volledig met lege voorspellingen in de real-time view per unieke data product key.
Lookup table-refresh
De batch layer genereert een lookup table die we in de speed layer nodig hebben om insights te genereren. Een Spark structured streaming static-stream join stelt ons in staat een opgeslagen DataFrame-lookup table te gebruiken in Spark structured streaming. Er is geen directe ondersteuning voor het herladen van deze “statische” DataFrame, behalve het herstarten van de stream processing.
Maar als we onze lookup table periodiek willen herladen om de nieuwste te krijgen, kunnen we een combinatie van “hacky” mechanismen gebruiken. Het opzetten van een “rate” readStream in combinatie met een functie die wordt aangeroepen na het verwerken van elke micro-batch om de statische DataFrame in de outer scope te herladen. Het is een beetje een hack, maar het lijkt te werken voor lookup tables die op disk zijn opgeslagen (zie 1 en 2).
Serving Layer
Ons AI-dataproduct wordt op twee manieren ontsloten: een REST API en twee eventhubs (batch en updates). De documentformaten tussen de batch- en real-time views zijn identiek en kunnen direct als JSON worden geserveerd, wat de complexiteit van de serving-logica in onze web app service verlaagt. Bij een request worden beide containers bevraagd op alle relevante voorspellingen. Er wordt slechts één voorspelling per business object teruggegeven en de real-time view heeft voorrang. Al met al hebben we het met onze aanpak in de huidige vorm eenvoudig gehouden. Laten we hopen dat we het eenvoudig kunnen houden!
Implementatie-wishlist
We hebben een aantal wensen om onze huidige Lambda-architectuur-implementatie uit te breiden. Deze zijn toegevoegd aan Figuur 6, namelijk:
- We zouden de batch- en updates-eventhub graag direct in CosmosDB sinken
- De eventhubs zouden ook een secundaire serving-capaciteit naar onze stakeholders vormen
- De Spark eventhub-verbinding throttlen om de maximaal benodigde eventhub throughput units te verlagen
- De mogelijkheid om voorspellingen in de speed layer opnieuw te berekenen op basis van voorgetrainde ML-modellen
- De mogelijkheid om een statische lookup table die in stream processing wordt gebruikt op elegante wijze te verversen

Wishlist-punt 3 kan worden bereikt volgens sectie 2.2 door een model registry (AzureML) toe te voegen om modellen die in de batch pipeline zijn getraind te registreren. Als MLOps besluit dat het nieuwste model beter is dan vorige modellen, deployen we het model voor inference met AzureML en sturen we de model API-URL naar de eventhub samen met het voorspellingsdatumbereik. We joinen de speed layer met de eventhub van model-URL’s op basis van de voorspellingsdatum en filteren de modellen die voor die datum geldig zijn. We kunnen de calls naar de model-API parallel afhandelen voor de streaming-berichten met een PySpark structured streaming Python UDF (voorbeeld op github). Als een nieuwe model-URL naar de eventhub wordt gepusht, genereert deze nieuwe insights voor zijn datumbereik, die de insight store-state in CosmosDB overschrijven. Deze aanpak om de “nieuwste” state in een document store op te lossen heet log projection en wordt door Microsoft verkozen boven log compaction (log projection). De andere twee wishlist-punten zijn afhankelijk van Microsoft en Databricks die ons de juiste tools leveren, of van het kiezen van andere technologieën. Zo kan Apache Druid een sink voor eventhubs zijn en een alternatief voor CosmosDB vormen. Bedankt voor je aandacht!