Elegante CICD met Databricks notebooks
Notebooks zijn op Databricks de primaire runtime, van data science-verkenning tot ETL en ML in productie. Deze nadruk op notebooks vraagt om een andere kijk op code van productiekwaliteit. We moeten onze terughoudendheid over rommelige notebooks loslaten en onszelf afvragen: hoe brengen we notebooks naar onze productiepijplijnen? Hoe voeren we unit- en integratietests uit op notebooks? Kunnen we notebooks behandelen als artifacts van een DevOps-pijplijn?
Databricks notebooks als first class citizens
Wanneer je Databricks kiest als compute-platform, is het je beste optie om notebooks ook in je productieomgeving te draaien. Deze beslissing wordt gedicteerd door de overweldigende ondersteuning voor de notebooks-runtime ten opzichte van klassieke python-scripting. Wij betogen dat je de notebooks-aanpak volledig moet omarmen en de beste methodes moet kiezen om notebooks te testen en te deployen in een productieomgeving. In deze blog gebruiken we Azure DevOps-pijplijnen voor het (unit- en integratie-)testen van notebooks met behulp van tijdelijke Databricks-clusters en het registreren van notebook-artifacts.
Notebooks: het startpunt van een python-package
Notebooks kunnen op zichzelf staan, maar wij hebben ze liever als onderdeel van een Git-repository, met de volgende structuur. Die bevat een notebooks-directory om Databricks-notebooks als Source-bestanden in te checken, een Python-package (‘my_model’) met functionaliteit die in een notebook geïmporteerd kan worden, een tests-directory met unit tests voor de Python-package, een Azure DevOps-pijplijn en een cluster-config.json om onze tijdelijke Databricks-clusters te configureren. Daarnaast gebruiken we Poetry voor het beheer van Python-dependencies en packaging op basis van de pyproject.toml-specificatie.
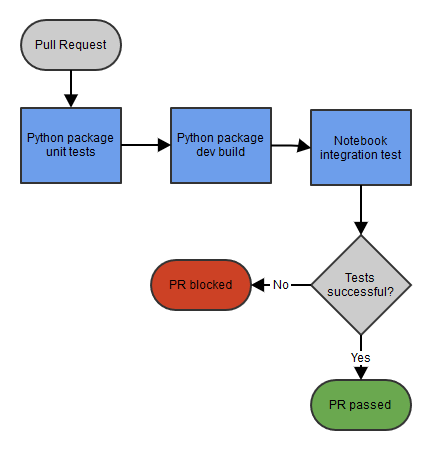
Notebook pull request-pijplijn
Bij het ontwikkelen van notebooks en de bijbehorende Python-package commit een ontwikkelaar op een development-branch en maakt een Pull Request aan zodat collega’s het kunnen reviewen. De Pull Request triggert automatisch een Azure DevOps-pijplijn die moet slagen op de meest recente commit. Eerst draaien we de unit tests van de Python-package en bij succes bouwen we deze en publiceren we de dev-build naar Azure Artifacts. De versie-string van deze dev-build-package wordt doorgegeven aan het notebook input-widget “package_version” voor integratietesten van het notebook op onze staging-omgeving. De pijplijn valideert of het notebook succesvol draait (of dbutils.notebook.exit wordt aangeroepen) en geeft feedback op de Pull Request.
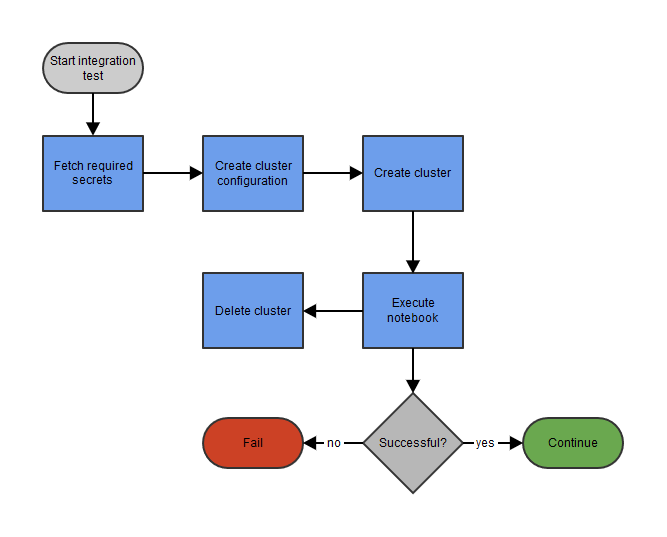
Integratietest op een tijdelijk cluster
Het doel is om dit notebook op Databricks uit te voeren vanuit een Azure DevOps-pijplijn. Voor flexibiliteit kiezen we Databricks Pools. Het voordeel van deze pools is dat ze de opstart- en autoscale-tijden van clusters kunnen verkorten wanneer veel verschillende jobs moeten draaien op just-in-time-clusters. Voor de uitvoering van het notebook (en toegang tot optionele databronnen) gebruiken we een Azure App Registration. Deze Azure App Registration krijgt rechten om Databricks-clusters te beheren en notebooks uit te voeren. De basisstappen van de pijplijn omvatten het configureren en aanmaken van een Databricks-cluster, het uitvoeren van het notebook en ten slotte het verwijderen van het cluster. We bespreken elke stap in detail.
Om Azure DevOps-pijplijnen te gebruiken voor het testen en deployen van Databricks-notebooks, gebruiken we de Azure DevOps tasks ontwikkeld door Data Thirst Ltd. Omdat hun set tasks nog niet alle benodigde operaties ondersteunt, gebruiken we ook de PowerShell tools die zij voor Databricks hebben ontwikkeld. Zowel de tasks als de PowerShell tools zijn wrappers rondom de Databricks API.
Databricks-rechten voor de App Registration
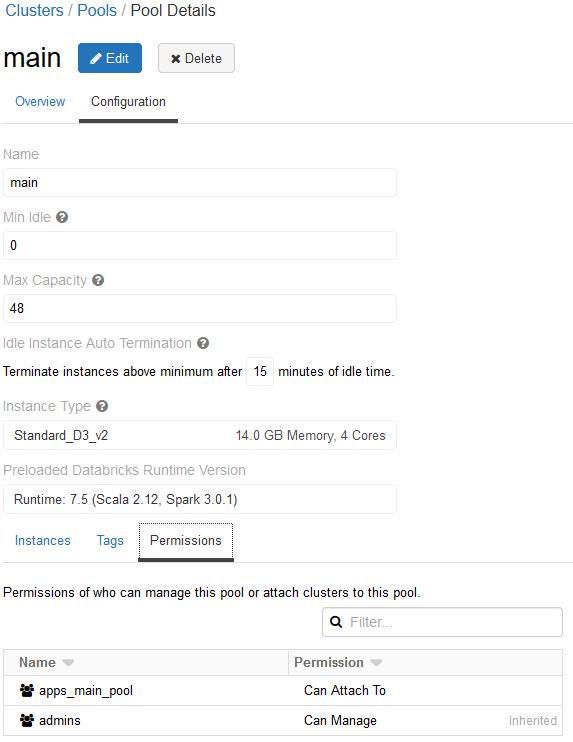
Ter voorbereiding maken we een Databricks-pool aan die beschikbaar is voor integratietesten. We gebruiken een Azure App Registration die optreedt als principal om notebooks uit te voeren op de instance pool. De App Registration wordt geregistreerd als Databricks Service Principal met de “Can Attach To”-permissie op de Databricks-pool om een cluster te kunnen aanmaken.
Pijplijn-secrets voorbereiden
De eerste stap van de CI/CD-pijplijn is het ophalen van alle benodigde secrets. Voor de eenvoud slaan we de client id, secret en tenant-id van de app registration en de Databricks pool ID op in een Key Vault. De secrets worden opgehaald met de AzureKeyVault task.
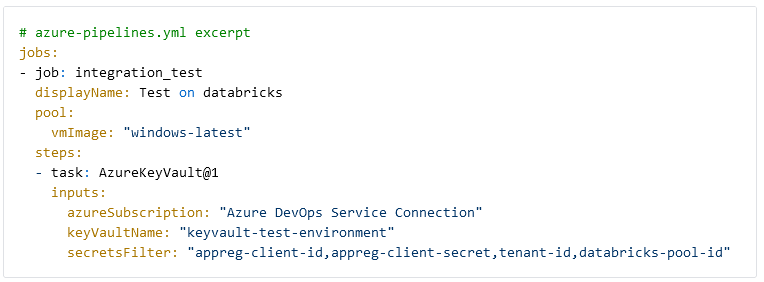
Verbinding met de Databricks-workspace
Om met Databricks te kunnen werken moeten we vanuit Azure DevOps verbinding maken met de workspace. We gebruiken twee Azure DevOps Tasks van Data Thirst om een access token voor Databricks te genereren en met de workspace te verbinden. Het token wordt opgeslagen in de BearerToken-variabele en gegenereerd voor de app registration waaraan we rechten hebben gegeven in Databricks. De workspace-URL is te vinden in de Azure Portal op de Databricks-resource.
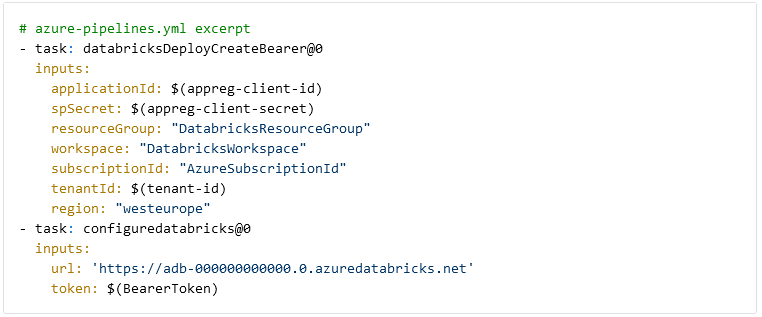
Let op: er is een potentieel beveiligingsprobleem bij het gebruik van de databricksDeployCreateBearer task, dat we in onze live pijplijnen hebben opgelost. De huidige versie van de task maakt bearer tokens aan zonder vervaldatum, en helaas is er geen manier om met de task een vervaldatum in te stellen. Als alternatief is het ook mogelijk om de PowerShell Databricks tools van Data Thirst te gebruiken. Door achtereenvolgens Connect-Databricks en New-DatabricksBearerToken aan te roepen, kun je een token met een beperkte levensduur aanmaken.
Een tijdelijk testcluster aanmaken
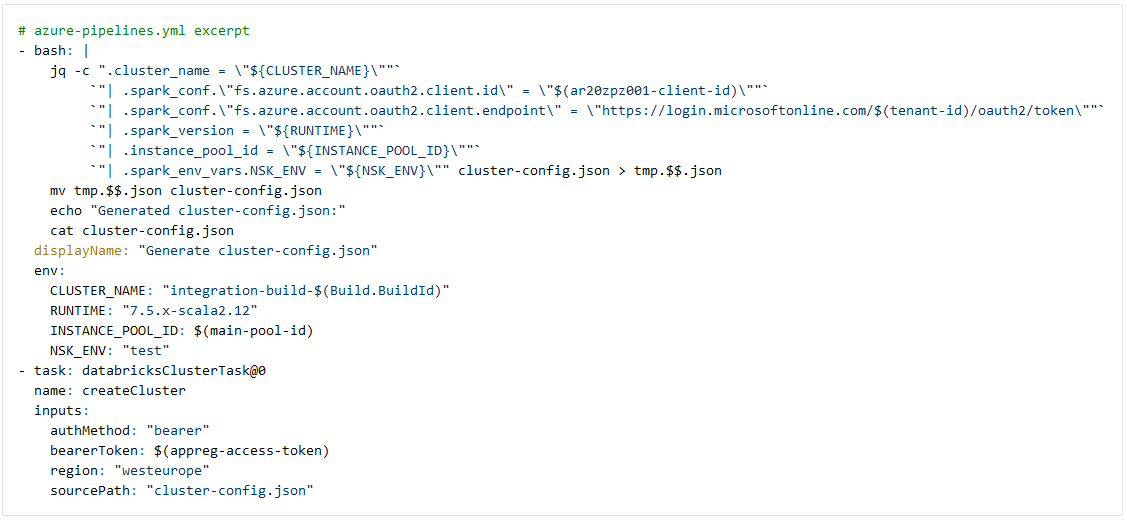
Na het opzetten van de verbinding met Databricks maken we in Databricks een toegewijd cluster aan voor de integratietesten die door deze pijplijn worden uitgevoerd. De clusterconfiguratie bestaat uit slechts 1 worker, wat voldoende is voor de integratietest. Omdat we testdata die voor de notebooks nodig is opslaan op een ADLS gen2-storageaccount, stellen we ADLS pass-through in zodat de app registration zich kan authenticeren bij het storageaccount. Als best practice plaatsen we de client secret van de app registration niet rechtstreeks in de clusterconfig, omdat deze dan zichtbaar is in Databricks. In plaats daarvan gebruiken we een Databricks Secret Scope en de bijbehorende template-markup in de clusterconfig, die op runtime wordt ingevuld.

We committen het bovenstaande template van het clusterconfiguratiebestand en gebruiken het linux-commando jq om details zoals de pool id en de client id van de app registration op runtime uit de Azure Key Vault in te vullen. De clusternaam is gebaseerd op de huidige devops Build ID en samen met andere parameters wordt de cluster-config.json gerenderd en naar schijf geschreven.
De databricksClusterTask van Data Thirst gebruikt de gerenderde cluster-config.json om een cluster aan te maken en te deployen op onze staging-omgeving met resources uit de Databricks-pool.
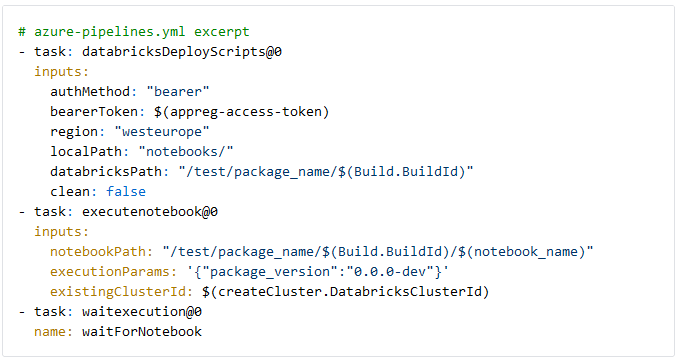
Notebook uitvoeren
Ten slotte kunnen we het te testen notebook uploaden en uitvoeren. De databricksDeployScripts task uploadt het notebook naar Databricks, dat vervolgens met de executenotebook task wordt uitgevoerd. Het notebook wordt opgeslagen in een pad dat de devops Build ID bevat, zodat het later geïdentificeerd (en verwijderd) kan worden indien nodig. Als het notebook widgets gebruikt, wordt de executionParams-input benut om een JSON-string met inputparameters door te geven. In ons geval wordt de dev-versie-string van de Python-package doorgegeven als “package_version” voor gecontroleerd integratietesten. Tot slot wachten we tot de uitvoering van het notebook is afgerond. De executenotebook task slaagt als de ingebouwde Databricks-functie dbutils.notebook.exit("returnValue") tijdens de notebook-run wordt aangeroepen.
Notebook-artifact release
Notebooks die succesvol getest zijn, zijn klaar om opgeslagen te worden voor gebruik in productiepijplijnen. We gebruiken Azure DevOps artifacts om de notebook-directory van het project te registreren als universal package in een Azure DevOps artifact feed. We zetten met sed een hard-coded default “package_version” in het notebook input-widget voordat we het notebook-artifact registreren, zie hieronder (voorbeeld release 1.0.0). De bijbehorende Python-package wordt ook als artifact geregistreerd met dezelfde naam en versie, maar in een andere DevOps artifact feed. Zo draait het notebook standaard met de Python-package-versie waarmee het getest is. Onze notebook-artifacts zijn daarmee reproduceerbaar en maken een gecontroleerd releaseproces mogelijk. Hoe je release-versies genereert, bepaal je zelf. In het begin kun je een git tag aan de main-branch toevoegen om een build inclusief artifact-registratie te triggeren. Voor volledige CICD kun je automatische versionering doen bij het mergen van een pull request.

Conclusie
We hebben laten zien hoe je integratietests voor notebooks draait op tijdelijke Databricks-clusters, samen met unit tests voor de Python-package. Dit resulteert in reproduceerbare notebook-artifacts die een gecontroleerd releaseproces voor notebooks mogelijk maken. Databricks-notebooks zijn first class citizens en vragen van engineers om notebooks te emanciperen binnen hun test- en releaseprocessen. We kijken ernaar uit om meer te leren over het samenbrengen van de realiteit van data scientists met die van de data engineer, met als doel de productiviteit te verhogen en regelmatig te releasen. Ons doel is om de stap van verkenning en proof-of-concept naar productie te vergemakkelijken. In onze volgende blog gaan we dieper in op het gebruik van notebook-artifacts in productiepijplijnen, met de nadruk op Azure Data Factory-pijplijnen.